Breast-cancer screening as anomaly ranking¶
This real sklearn dataset is a useful reality check. The classes are not generated by a covariance model, so robustcov should not be expected to dominate all baselines.
Result at a glance¶
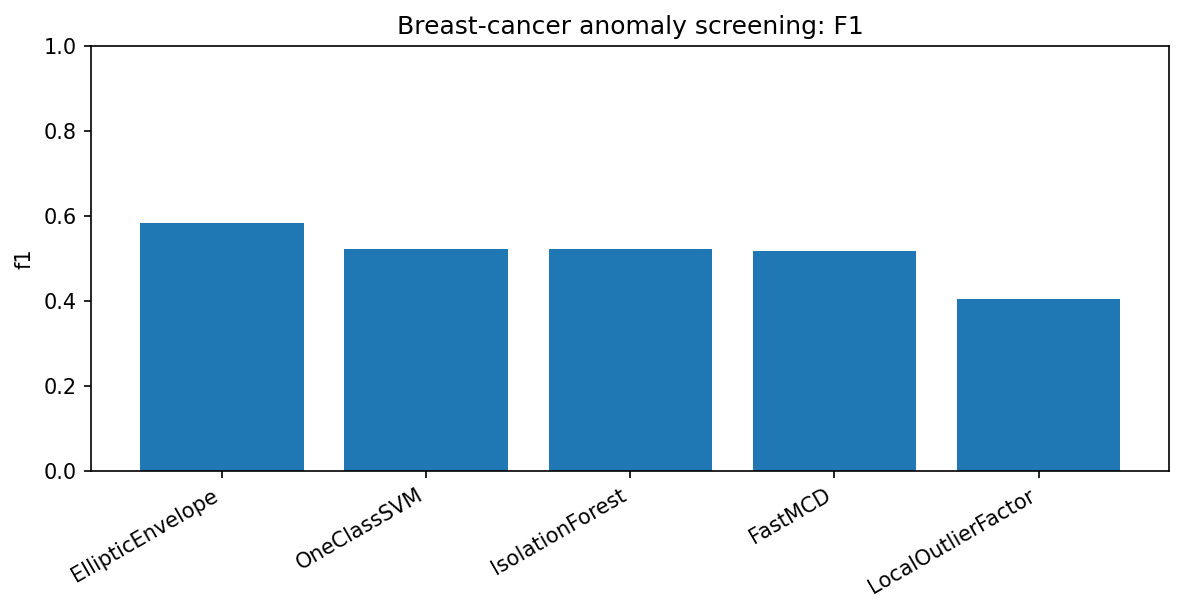
EllipticEnvelope has the best F1 in this run. FastMCD is close to IsolationForest and OneClassSVM but not best. This is a valuable honest example: robust distances are competitive diagnostics, not universal winners.
What the data represent¶
The example uses the sklearn breast-cancer dataset with a reduced feature representation. One class is treated as the anomaly class for an unsupervised screening comparison.
Why this estimator¶
FastMCD is included as an interpretable robust-distance baseline. It is compared with common sklearn anomaly detectors.
Reproduce the result¶
python examples/use_case_breast_cancer_screening.py
Output from the run¶
breast-cancer anomaly screening
method,seconds,precision,recall,f1,roc_auc,detected
sklearn EllipticEnvelope,0.5495,0.5849,0.5849,0.5849,0.7426,212
sklearn OneClassSVM,0.0130,0.5236,0.5236,0.5236,0.6601,212
sklearn IsolationForest,0.1384,0.5236,0.5236,0.5236,0.6770,212
robustcov FastMCD,0.0678,0.5189,0.5189,0.5189,0.6829,212
sklearn LocalOutlierFactor,0.0079,0.4057,0.4057,0.4057,0.5356,212
n=569, p=12, anomaly_fraction=0.373
robust_radial_kurtosis=6.933
saved diagnostics to results/use_cases/breast_cancer
Figures and diagnostics¶
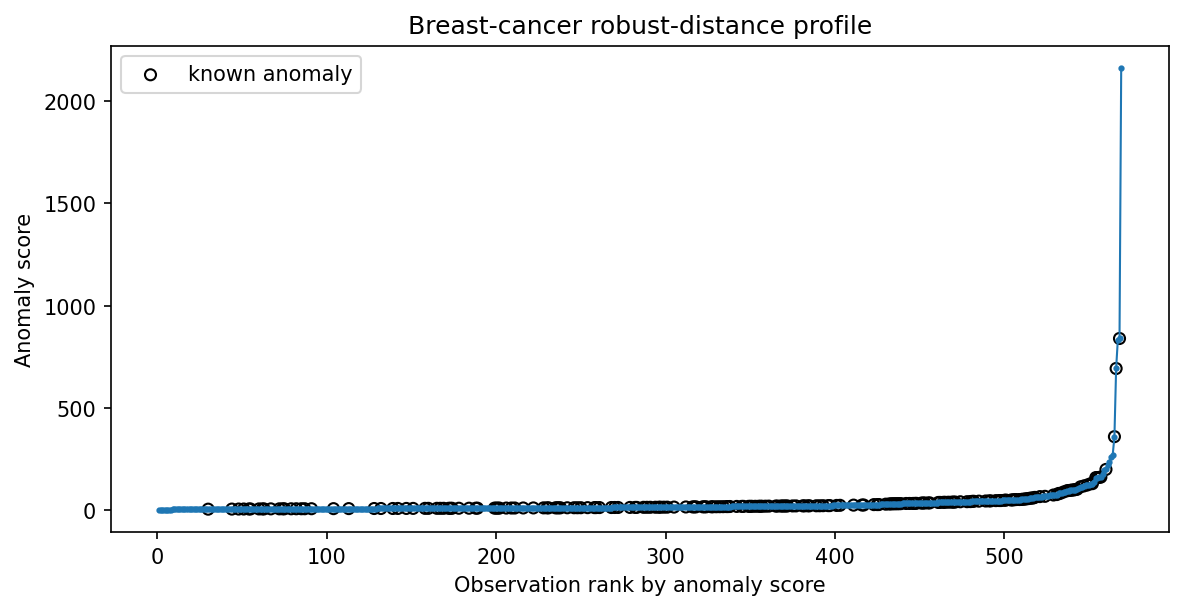
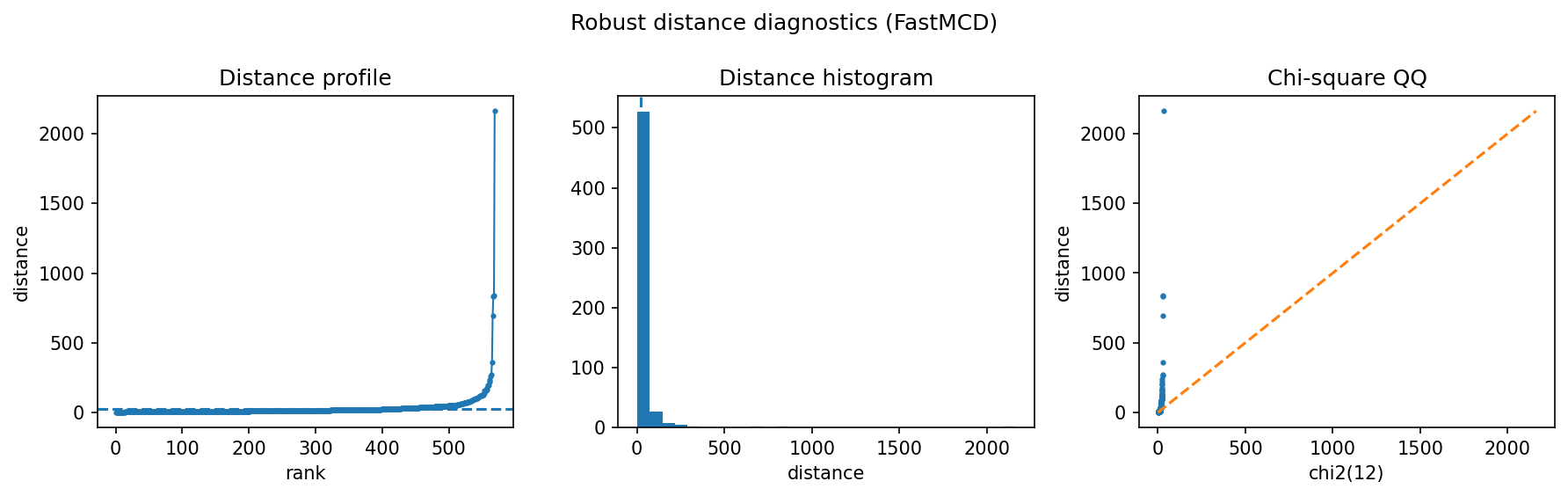
How to read the result¶
Look at both F1 and ROC-AUC. Similar F1 values can hide different score rankings, and score rankings matter if the practical task is review prioritization.
What this does not prove¶
For medical datasets, supervised clinical models and feature engineering are usually necessary. robustcov should be framed as an interpretable screening score.