Benchmark gallery¶
The benchmark gallery is the main benchmark entry point. It is designed for readers who want to understand the evidence quickly: each card links to a focused benchmark page with plots, tables, commands, and interpretation.
The gallery answers four practical questions:
Which estimator works best for small-sample heavy-tailed covariance?
How much faster is
robustcovthan common sklearn robust-covariance baselines?Does optional OpenMP parallelism help at larger scale?
Where do robust covariance methods work well, and where do they fail?
Gallery cards¶
Small-sample heavy-tail ranking
Regularized Cauchy, Student-t scatter, Tyler variants, MCD, Ledoit-Wolf, OAS, and empirical covariance compared across n, p, and tail weight.
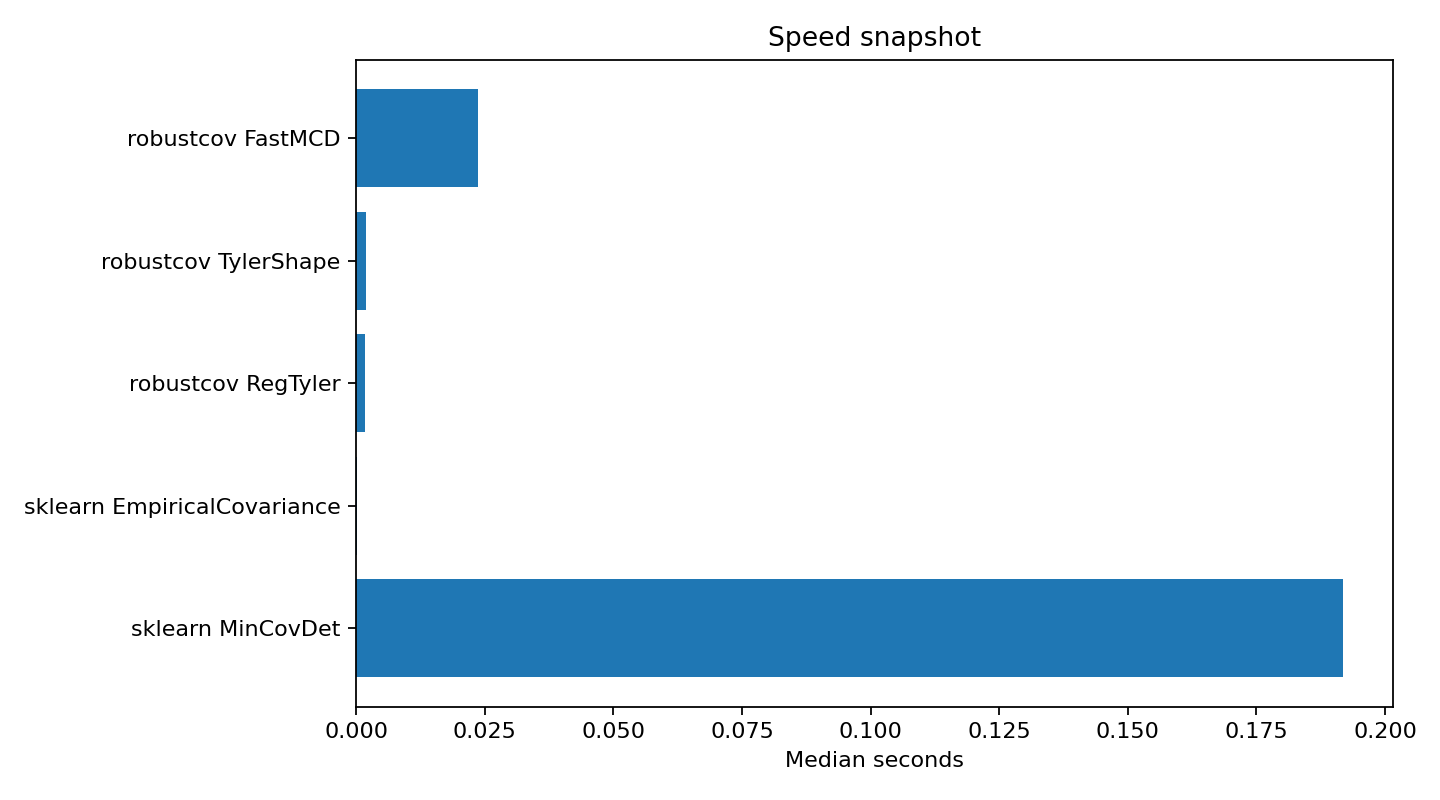
Speed comparison
FastMCD and Tyler-family timing against sklearn covariance baselines in a representative contamination setting.
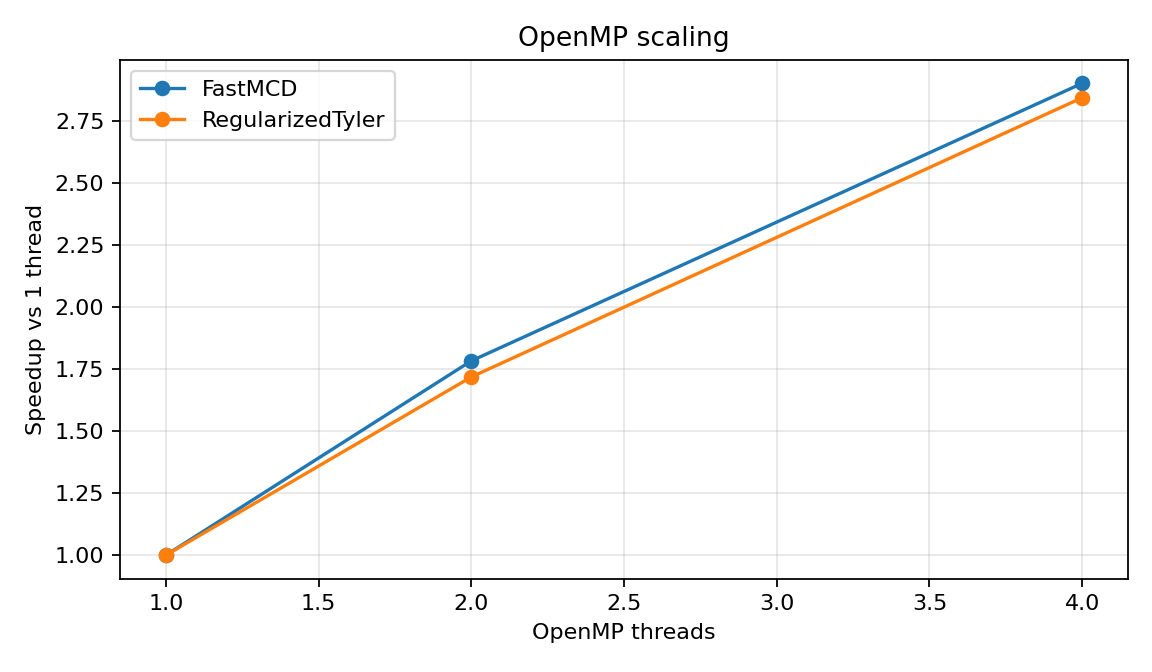
OpenMP scaling
Thread scaling for the C++ kernels used by FastMCD and RegularizedTyler.
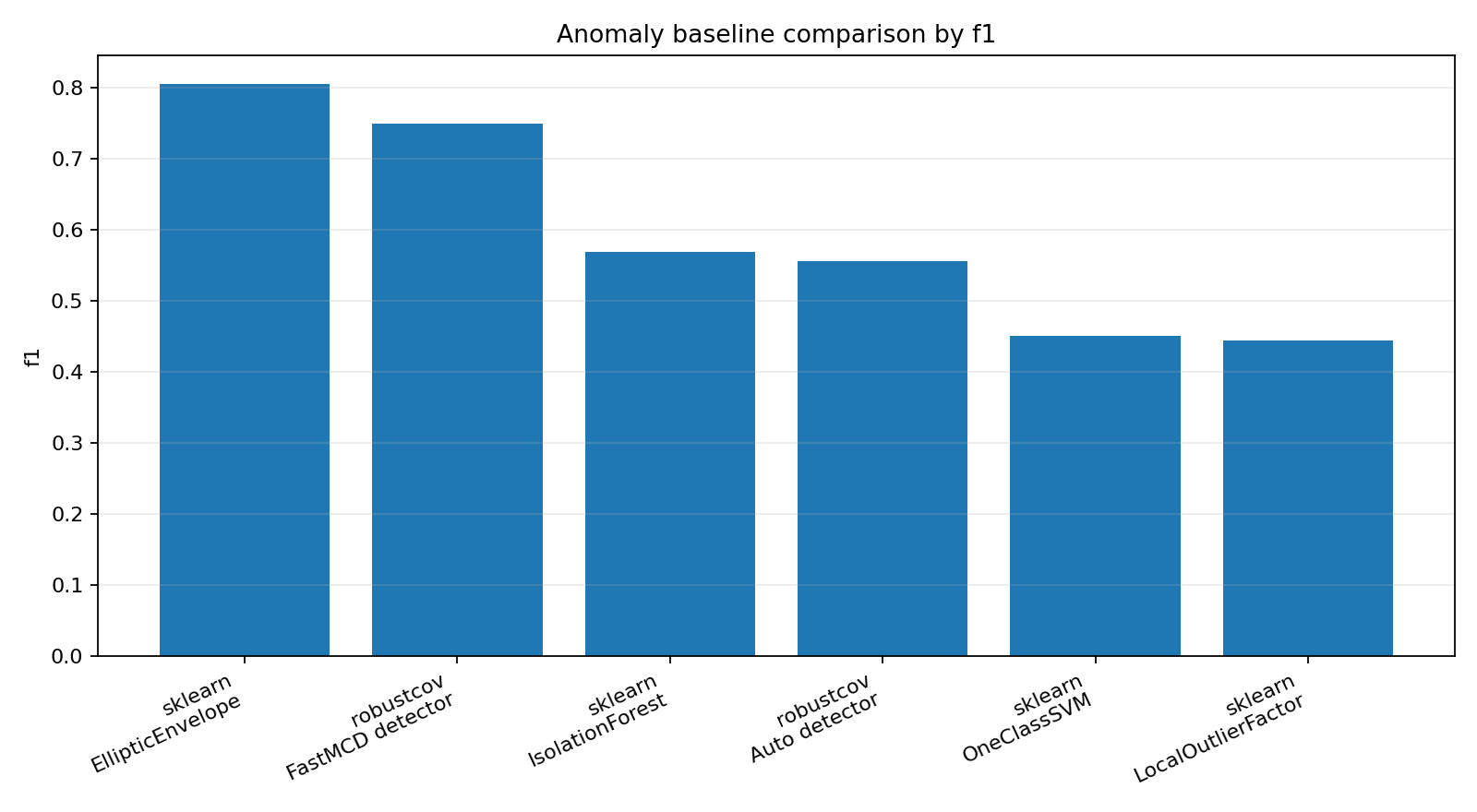
Anomaly detection baselines
Robust distance detectors compared with IsolationForest, LOF, OneClassSVM, and EllipticEnvelope.
scenarios
Hard contamination scenarios
Mean shift, clustered contamination, variance contamination, leverage points, and heavy-tail inliers.
Recommended benchmark workflow¶
Run the full report generator when you want the same assets used by the documentation:
OMP_NUM_THREADS=4 OPENBLAS_NUM_THREADS=1 MKL_NUM_THREADS=1 \
python benchmarks/make_report.py --outdir results/report
This writes a standalone HTML report, Markdown report, CSV files, and plots.
results/report/benchmark_report.html
results/report/benchmark_report.md
results/report/small_sample.csv
results/report/small_sample_summary.csv
results/report/small_sample_rank.png
results/report/speed.csv
results/report/speed.png
results/report/openmp_scaling.csv
results/report/openmp_scaling.png
results/report/anomaly_baselines.csv
results/report/anomaly_baselines.png
results/report/hard_scenarios.csv
How to read the gallery¶
A single benchmark row is rarely enough. Prefer rank summaries, median error, win rate, and
scenario-specific interpretation. RegularizedCauchy is usually the strongest small-sample
heavy-tail covariance estimator. FastMCD is the classical choice for separable contamination
when the uncontaminated majority is well defined. RegularizedTyler is best described as a
robust shape estimator and should not be advertised as the universal covariance-recovery winner.