IEEE-CIS fraud¶
Status¶
Best quality among tested unsupervised baselines, but slow
RegularizedCauchy achieved the best F1, ROC-AUC, and PR-AUC among the
tested unsupervised baselines, but it was much slower than
IsolationForest. This should be reported as a quality/interpretability
result, not as a speed win.
Why this matters¶
IEEE-CIS is a large heterogeneous tabular fraud dataset. It contains mixed numeric/categorical behavior, missingness, and fraud signals that are often better handled by supervised gradient boosting. This makes it a good stress case for honest reporting: robust covariance can help, but it is not a magic solution for all tabular fraud problems.
Result summary¶
Method |
F1 |
PR-AUC |
ROC-AUC |
Seconds |
|---|---|---|---|---|
robustcov RegularizedCauchy |
0.1550 |
0.0931 |
0.7641 |
1367.0149 |
sklearn IsolationForest |
0.1390 |
0.0838 |
0.7387 |
1.1571 |
sklearn EllipticEnvelope |
0.0914 |
0.0753 |
0.7578 |
3045.0699 |
sklearn LocalOutlierFactor |
0.0633 |
0.0452 |
0.6539 |
27.7558 |
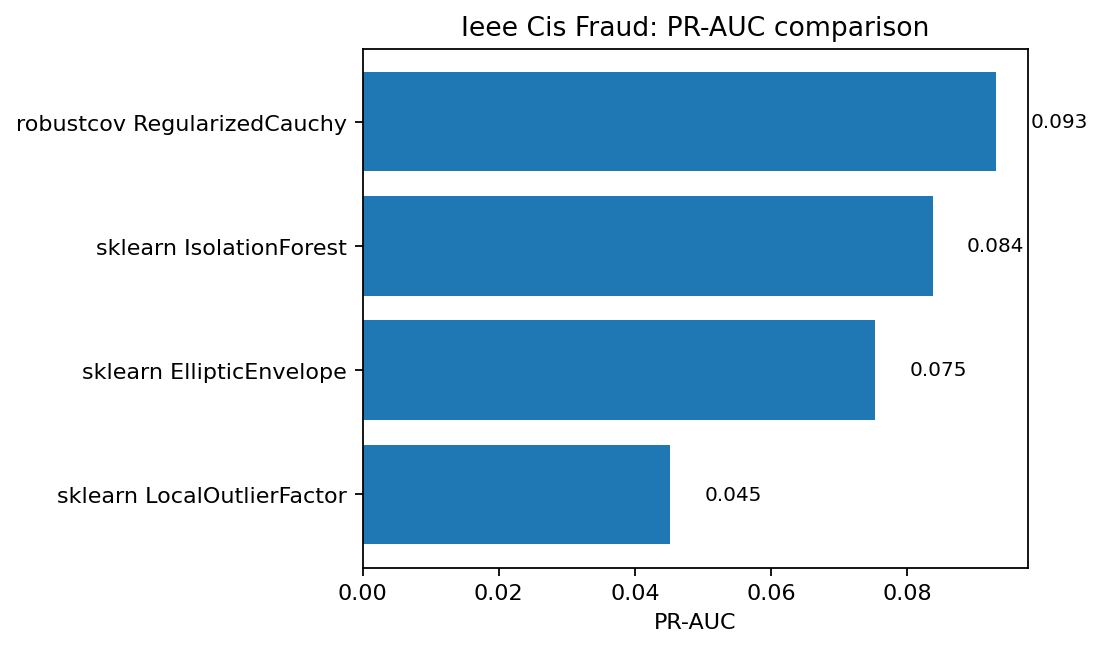
PR-AUC comparison. RegularizedCauchy gives the best quality among these
unsupervised baselines, but the margin over IsolationForest is modest.¶
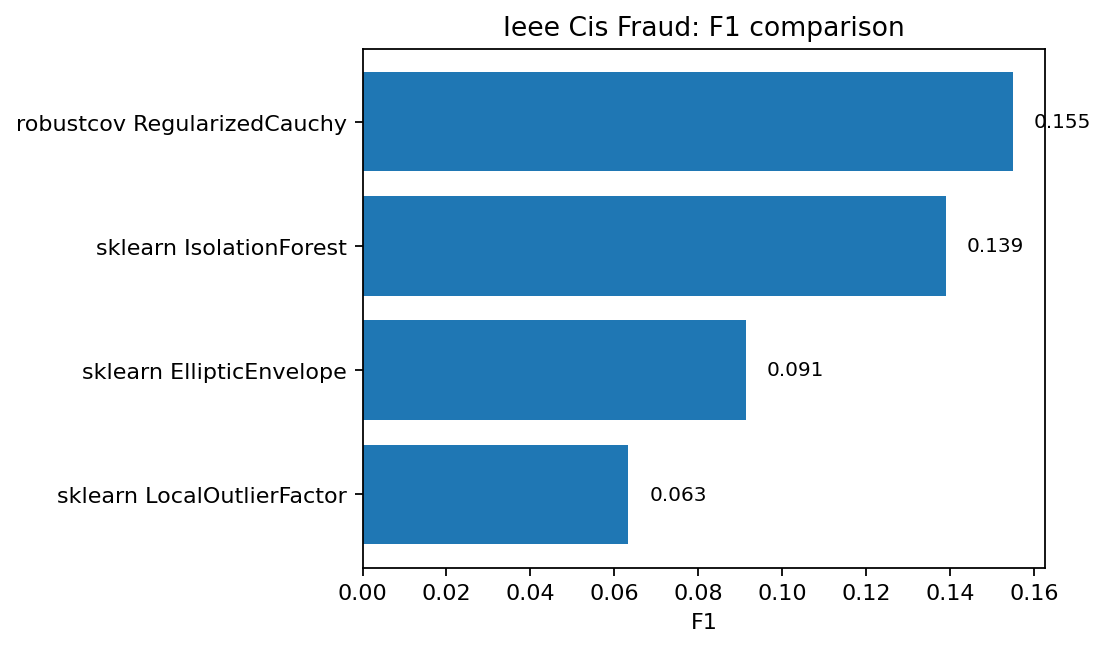
F1 comparison at the same detection budget.¶
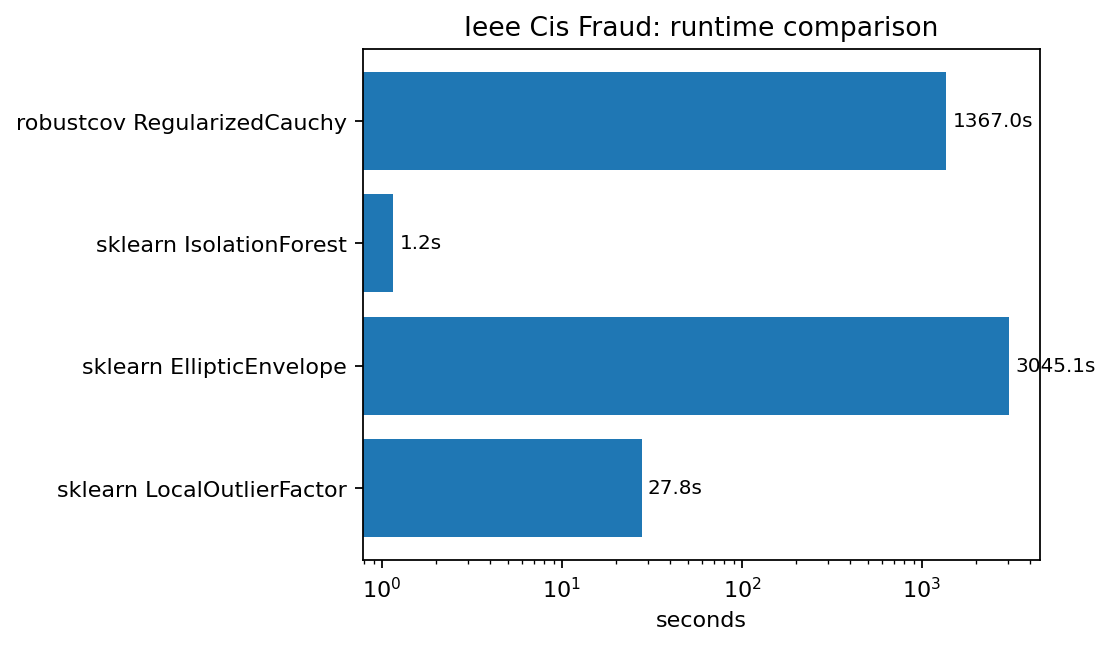
Runtime comparison on a log scale. The large runtime gap is the main reason
this result is classified as competitive/slow rather than a strong win.¶
Output from the run¶
IEEE-CIS fraud benchmark
method,seconds,precision,recall,f1,roc_auc,pr_auc,detected
robustcov RegularizedCauchy,1367.0149,0.1550,0.1550,0.1550,0.7641,0.0931,2561
sklearn IsolationForest,1.1571,0.1390,0.1390,0.1390,0.7387,0.0838,2561
sklearn EllipticEnvelope,3045.0699,0.0914,0.0914,0.0914,0.7578,0.0753,2561
sklearn LocalOutlierFactor,27.7558,0.0633,0.0633,0.0633,0.6539,0.0452,2561
saved outputs to results/external/ieee_cis_fraud
Interpretation¶
This benchmark is useful but should be framed carefully. RegularizedCauchy
improves unsupervised quality metrics, but the dataset is large and heterogeneous
and the runtime is not yet competitive with IsolationForest. In practice,
this robust anomaly score is most useful as an additional feature for a larger
fraud pipeline, or as an interpretable unsupervised diagnostic.
Engineering follow-up¶
The next improvement for large Kaggle-style tabular data is a sampled-fit/full- score mode, for example fitting the robust scatter on 50k representative rows and scoring all rows. This would preserve much of the robust-distance signal while making the workflow much faster.