OpenMP scaling benchmark¶
Question¶
Does optional OpenMP parallelism improve speed on larger workloads?
Design¶
The benchmark runs the same estimator with different thread counts. BLAS thread counts should be set to one so OpenMP and BLAS do not oversubscribe the CPU.
OMP_NUM_THREADS=4 OPENBLAS_NUM_THREADS=1 MKL_NUM_THREADS=1 \
python benchmarks/openmp_scaling.py --n 8000 --p 20 --threads 1 2 4
Scaling table¶
method |
threads |
median_seconds |
min_seconds |
max_seconds |
speedup_vs_1 |
|---|---|---|---|---|---|
FastMCD |
1 |
0.679777 |
0.679550 |
0.683289 |
1.000 |
FastMCD |
2 |
0.381042 |
0.377283 |
0.381148 |
1.784 |
FastMCD |
4 |
0.234113 |
0.232033 |
0.240740 |
2.904 |
RegularizedTyler |
1 |
0.027655 |
0.026847 |
0.031376 |
1.000 |
RegularizedTyler |
2 |
0.016086 |
0.015778 |
0.017262 |
1.719 |
RegularizedTyler |
4 |
0.009717 |
0.009653 |
0.015875 |
2.846 |
Plot¶
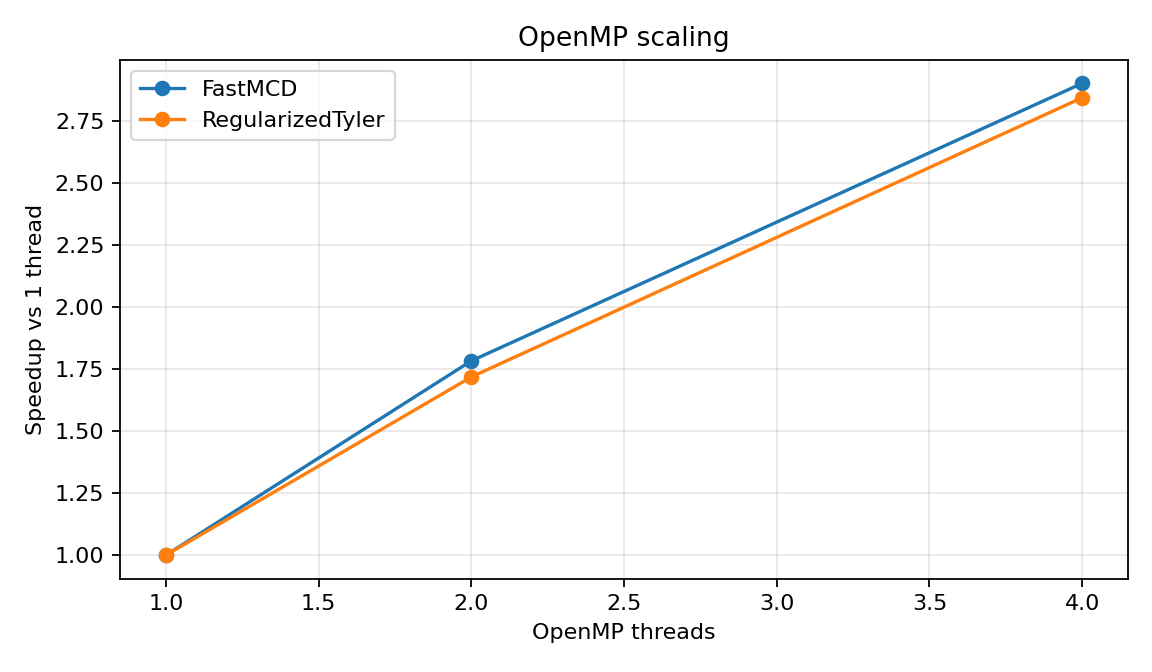
Interpretation¶
OpenMP helps most when the workload has enough rows, enough features, or enough random starts to pay for threading overhead. Small examples may not speed up because thread startup and scheduling costs dominate. In larger benchmark settings, robust distance evaluation, covariance accumulation, Tyler updates, and FastMCD candidate evaluation can all benefit.
Practical advice¶
Use explicit environment variables for reproducible timing:
OMP_NUM_THREADS=4 OPENBLAS_NUM_THREADS=1 MKL_NUM_THREADS=1
Inside Python, users can also control the package thread count:
import robustcov as rc
print(rc.has_openmp())
rc.set_num_threads(4)
est = rc.FastMCD(n_jobs=4, random_state=0).fit(X)